application desktop multiplateforme, compatible Windows, macOS et Linux.
Avec NativePHP v1.0.0, l’écosystème Laravel franchit un cap : il devient possible de créer des
applications desktop distribuables tout en capitalisant sur votre code PHP existant.
Chez Any In IT, nous suivons ces approches « web-to-desktop » qui accélèrent la création d’outils métiers,
d’applications grand public et de logiciels internes.

Sommaire
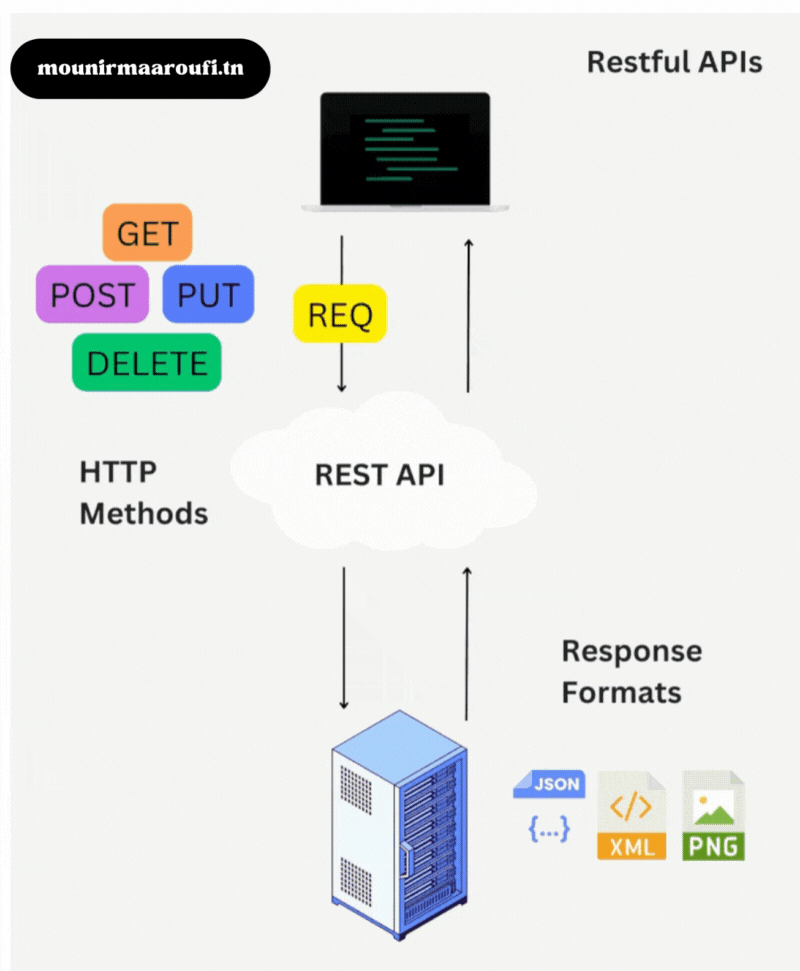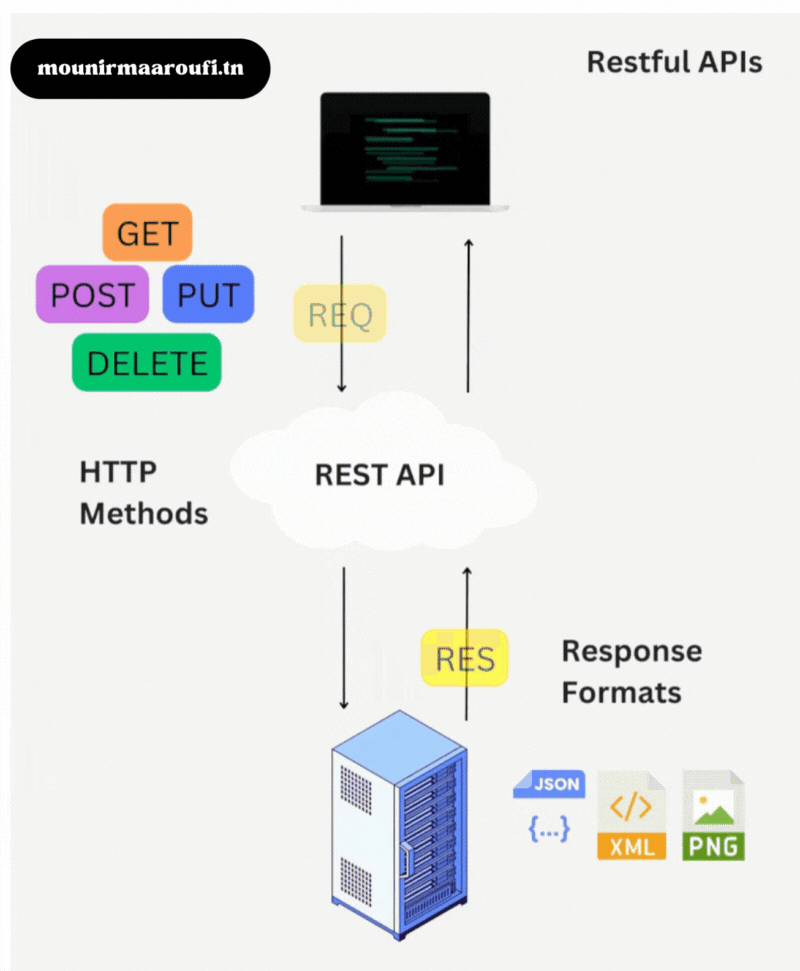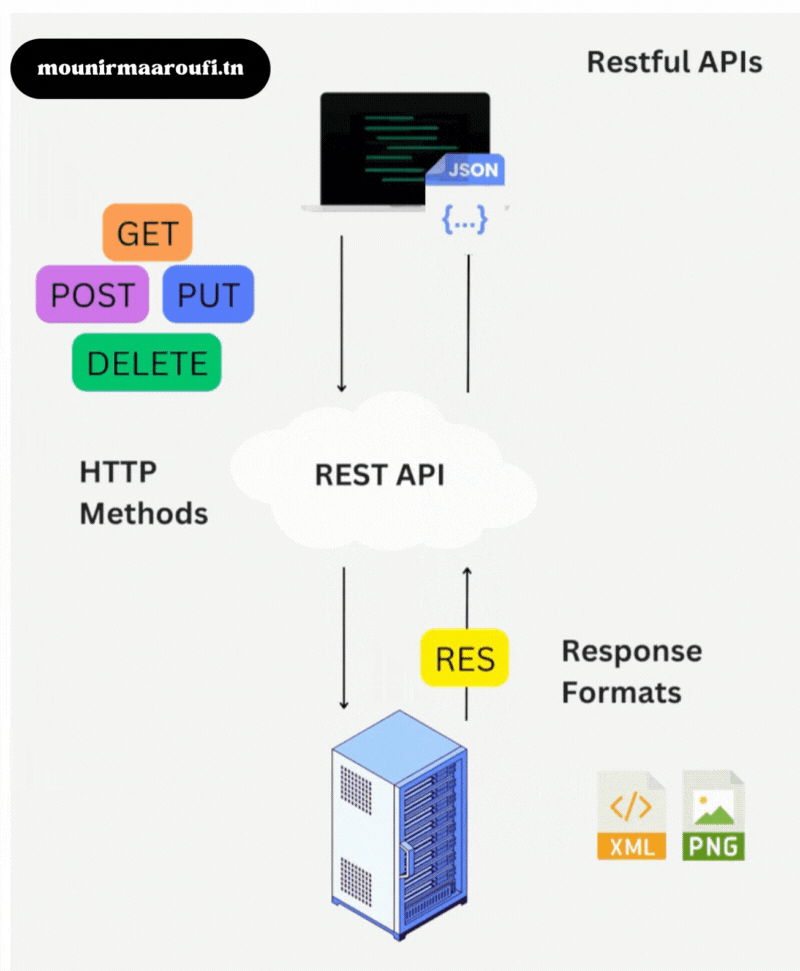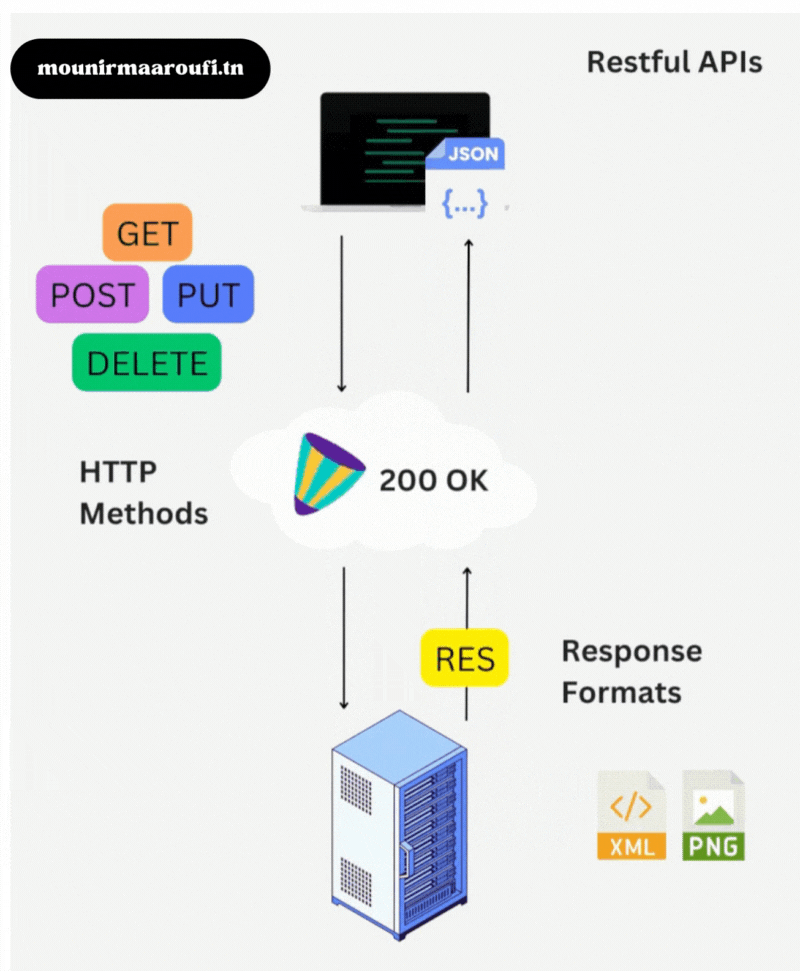
1) Qu’est-ce que NativePHP Laravel ?
NativePHP Laravel est une solution qui permet de transformer un projet Laravel en application de bureau.
L’objectif : conserver les avantages de Laravel (routing, authentification, jobs, base de données, validation, etc.)
tout en offrant une expérience utilisateur « desktop ».
Les points forts
- Applications distribuables : génération de packages/exécutables selon l’OS.
- Multiplateforme : Windows, macOS et Linux.
- Approche Laravel-first : vous restez dans l’écosystème PHP/Laravel.
Pour les détails techniques et les commandes de build, consultez la
documentation officielle NativePHP.
2) NativePHP Laravel : 7 avantages puissants pour créer des applications desktop
1. Réutiliser vos compétences Laravel
Vous développez avec Laravel, vous gardez vos habitudes : structure du projet, logique métier, services, validation et
bonnes pratiques. Cela réduit fortement la courbe d’apprentissage.
2. Accélérer le time-to-market
Pour un outil interne ou un MVP, vous passez plus vite de l’idée à une application installable, sans repartir de zéro
sur une stack desktop différente.
3. Distribution plus simple
L’utilisateur final installe l’application comme un logiciel classique. C’est utile pour des contextes où l’accès web
n’est pas toujours optimal ou lorsque l’on vise une expérience “app” plus native.
4. UX plus « OS-friendly »
Les applications desktop permettent d’exploiter des comportements attendus par les utilisateurs : intégration système,
accès local aux fichiers, notifications, fenêtres, etc.
5. Adapté aux outils métiers
Tableaux de bord, back-offices, outils d’administration, gestion d’inventaire… Le desktop peut améliorer le confort de
travail sur poste fixe et simplifier certains usages (import/export de fichiers, automatisations locales).
6. Une base solide pour des logiciels hybrides
Vous pouvez concevoir une application qui fonctionne en mode connecté (API) et, selon l’architecture, conserver une
partie des fonctionnalités en local.
7. Meilleure adoption en entreprise
Dans certains environnements, un logiciel installable est plus facile à déployer, documenter et standardiser qu’une
multitude d’outils web dispersés.
3) Prérequis et compatibilité
NativePHP v1.0.0 s’aligne sur des versions modernes. Assurez-vous d’avoir un projet compatible
(notamment Laravel 11+ et PHP 8.3+), puis vérifiez la compatibilité de vos packages tiers avant le packaging.
4) Installation et démarrage
Installation (Composer)
composer require nativephp/laravel
Ensuite, suivez les étapes de configuration dans la documentation pour générer votre build desktop.
Pensez à tester votre application (auth, DB, jobs, notifications) avant de produire un package final.
Pour un accompagnement sur l’architecture, la sécurité ou l’industrialisation, découvrez notre service
développement Laravel & solutions sur mesure.
5) Cas d’utilisation
a) Outils internes
Gestion de tâches, dashboards, outils d’admin, connecteurs de données : le desktop est souvent pertinent pour les équipes
back-office et les postes fixes.
b) Applications grand public
Productivité, utilitaires, gestion financière : Laravel apporte une base solide, et l’app desktop améliore l’expérience
pour certains usages.
c) Logiciels métiers (ERP / CRM)
Sur des modules spécifiques, une interface desktop peut compléter une app web et faciliter l’adoption selon le contexte
(réseau, sécurité, usage terrain, etc.).
Conclusion
NativePHP Laravel ouvre une voie intéressante pour créer des applications desktop multiplateformes à partir
d’un projet Laravel. Pour les outils métiers et les besoins internes, c’est une option sérieuse à évaluer.
Besoin d’un accompagnement ?
Vous voulez valider la faisabilité (stack, packaging, sécurité, distribution) ? Parlons-en.
👉 Contactez Mounir Maaroufi pour une étude rapide et des recommandations techniques.
FAQ
NativePHP remplace-t-il Electron ?
Pas forcément. Ce sont des approches différentes. NativePHP vise surtout les développeurs Laravel qui veulent livrer du desktop
en restant dans leur écosystème PHP.
Peut-on réutiliser une application Laravel existante ?
Oui. C’est l’un des avantages : capitaliser sur un projet existant, puis adapter l’interface et les besoins desktop.
Est-ce adapté à une application entreprise (ERP / CRM) ?
Oui, surtout pour des modules internes ou des postes fixes. Le choix dépend de contraintes réseau, sécurité, distribution et mises à jour.









")